Explorations in Vectorization
When we enter into the computer coding realm, most learners are introduced to the for loop. This loop iterates over a list of elements and BAM!, the loop does its magic and we get an output. This is a scalar operation because it takes each element individually and operates it over one at a time.
However, CPU’s nowadays can do more than that. Instead of a for loop we can actually tell the computer to operate over the entire object all at once saving much time in the process. This is the process of ‘vectorization’ — to simultaneously operate over the entire list, np.array, or data frame etc. thus churning out the output hundreds or thousands of times faster. The computer processing is called parallel computing in which your data is spread over 2 or 4 core processors within the CPU and computed at the same time. Then it gets recombined, but essentially it’s four people doing the work of what in the past was done by one person.
Thru my exploration in vectorization, you will see that for loops should be avoided and how the philosophy of vectorization optimizes speed.
Python is a high-level language as opposed to a low-level language such as C++. C++ is more related to the native language of computers (which is binary) while Python has several layers of translation before it reaches the user interface. The advantage of this is that Python is more readable and user-friendly. The disadvantage is the time loss due to multiple layers of translation. Thus the language will never be as fast as C++ which interacts more directly with the computer. The NumPy package speeds up Pandas because NumPy actually does its computations in C++ and returns it back in Python language.
I will now try different functions that will do the same thing hopefully to illustrate the speed gains from vectorization. I used a timeit module to time my runtime. I shall do this first with just a text search over a small data set and then a heavy computation for a large list of numbers. And then an exploratory analysis of the given Haversine formula.
For my first example, I decided to do a list search for the countries that begin with the letter z — first with a for loop, and then a more direct method. First I imported the necessary libraries and packages.

then loaded my data

Then I ran my for loop

and then ran my vectorization code

As you can see the direct approach without iterating thru the data frame was many, many times faster. Thus, one sees the speed gains thru vectorization.
For my computational experiment, I wanted to see if different approaches in coding would be faster or slower in giving me the desired output.
I used the same approach, this time for a large np.array of integers. I created my data.

Ran it thru a for loop and timed it

I tried using list comprehension to see if there’s a difference

And even used an .apply method

From these three examples, the list comprehension is the fastest by fractions of a second because it uses the individual iteration method the least. In the for loop as well as the .apply method, each element is being operated on and therefore the slowest.
Next, I looked on the web for a popular example on vectorization optimization. This example was given by Sofia Heisler in her PyCon talk in May 2017. She used the Haversine formula that calculated the distance between two locations, given their coordinates.

She used an example of the for loop to illustrate and compare to vectorization. This was her for loop
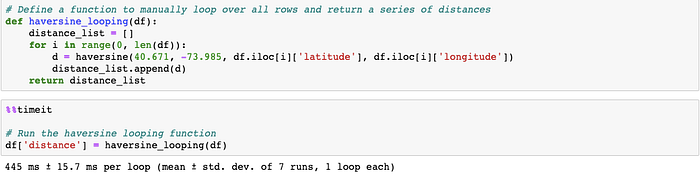
And we see how much time it took compared with an .apply method

Which speeded it up about 6x and than compared it to the vectorization method

This was her computation on a Pandas Series, but it can further be optimized with a np.array

And finally, what took about 445 milliseconds (44.5 hundredths of a second) is shrunk down to 4.92 microseconds (49 millionths of a second).
In closing, vectorization is a strategy and concept in coding that should be implemented because it optimizes our time. It is efficient, and pushes us to code in better ways, as well as challenges us to streamline what we thought was already fast. For loops was our foundations and building blocks as we learn to code, but we must all make that leap forward as data scientists to evolve and become more efficient. Learning the complexities of the computer tell us how data is stored and manipulated ‘under the hood.’ This gives us knowledge as to what’s happening but it is up to us to use the tools provided to maximize our output. Through my own exploration and other’s illustrations, I have a firmer understanding of how vectorization works which I shall carry through in my coding experiences.
